Research
My research has largely focused on developing general goal representations for deep RL, imitation learning, and model-based RL problems. You can view my dissertation here!
Ashley D. Edwards, Himanshu Sahni, Rosanne Liu, Jane Hung, Ankit Jain, Rui Wang, Adrien Ecoffet, Thomas Miconi, Charles Isbell, Jason Yosinski
In this paper, we introduce a novel form of a value function, Q(s, s' ), that expresses the utility of transitioning from a state s to a neighboring state s' and then acting optimally thereafter. In order to derive an optimal policy, we develop a novel forward dynamics model that learns to make next-state predictions that maximize Q(s, s' ). This formulation decouples actions from values while still learning off-policy. We highlight the benefits of this approach in terms of value function transfer, learning within redundant action spaces, and learning off-policy from state observations generated by sub-optimal or completely random policies.
This work was accepted into ICML 2020.
Ashley D. Edwards, Himanshu Sahni, Yannick Schroecker, Charles L. Isbell
In this paper, we describe a novel approach to
imitation learning that infers latent policies directly from state observations. We introduce a
method that characterizes the causal effects of latent actions on observations while simultaneously
predicting their likelihood. We then outline an
action alignment procedure that leverages a small
amount of environment interactions to determine
a mapping between the latent and real-world actions. We show that this corrected labeling can
be used for imitating the observed behavior, even
though no expert actions are given. We evaluate our approach within classic control environments and a platform game and demonstrate that
it performs better than standard approaches.
This work was accepted into ICML 2019.
Ashley D. Edwards, Charles L. Isbell

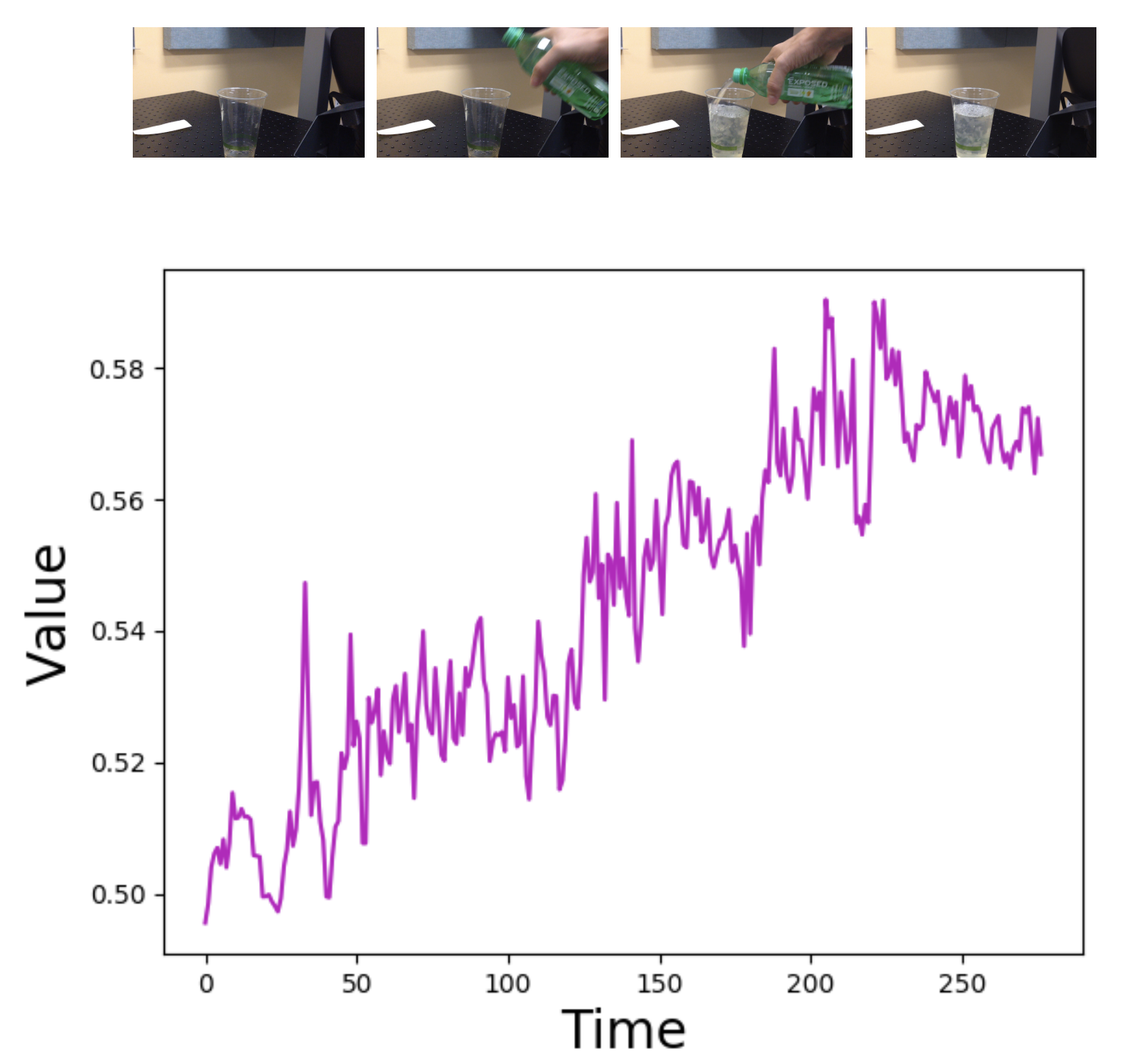
Imitation by observation is an approach for learning from expert demonstrations that lack action information, such as videos. Recent approaches to this problem can be placed into two broad categories: training dynamics models that aim to predict the actions taken between states, and learning rewards or features for computing them for Reinforcement Learning (RL). In this paper, we introduce a novel approach that learns values, rather than rewards, directly from observations. We show that by using values, we can significantly speed up RL by removing the need to bootstrap action-values, as compared to sparse-reward specifications.
This work was accepted into the Workshop on Self-Supervised Learning at ICML 2019.
Ashley D. Edwards, Laura Downs, James C. Davidson
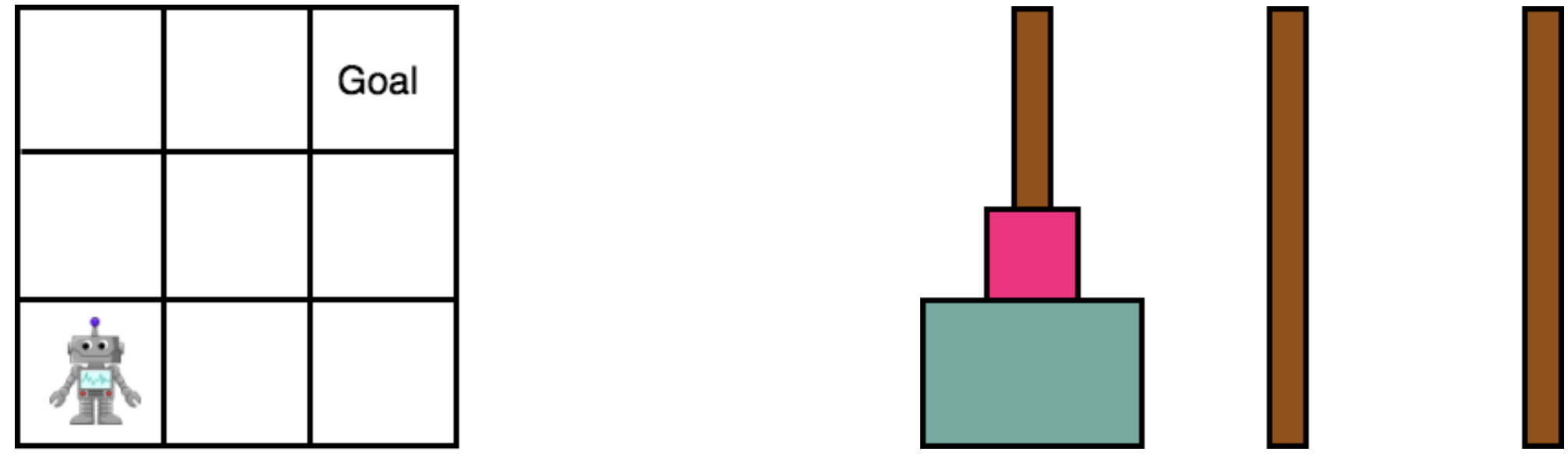
Goals for reinforcement learning problems are typically defined through hand-specified rewards. To design such problems, developers of learning algorithms must inherently be aware of what the task goals are, yet we often require agents to discover them on their own without any supervision beyond these sparse rewards. While much of the power of reinforcement learning derives from the concept that agents can learn with little guidance, this requirement greatly burdens the training process. If we relax this one restriction and endow the agent with knowledge of the reward function, and in particular of the goal, we can leverage backwards induction to accelerate training. To achieve this, we propose training a model to learn to take imagined reversal steps from known goal states. Rather than training an agent exclusively to determine how to reach a goal while moving forwards in time, our approach travels backwards to jointly predict how we got there. We evaluate our work in Gridworld and Towers of Hanoi and empirically demonstrate that it yields better performance than standard DDQN.
This work was accepted into the Machine Learning in Planning and Control of Robot Motion
workshop at ICRA in 2018.
Ashley D. Edwards, Charles L. Isbell
A major bottleneck for developing general reinforcement learning agents is determining rewards that will yield desirable behaviors under various circumstances. We introduce a general mechanism for automatically specifying meaningful behaviors from raw pixels. In particular, we train a generative adversarial network to produce short sub-goals represented through motion templates. We demonstrate that this approach generates visually meaningful behaviors in unknown environments with novel agents and describe how these motions can be used to train reinforcement learning agents.
This work was accepted into the Deep Reinforcement Learning Symposium at NIPS in 2017.
Ashley D. Edwards, Srijan Sood, Charles L. Isbell
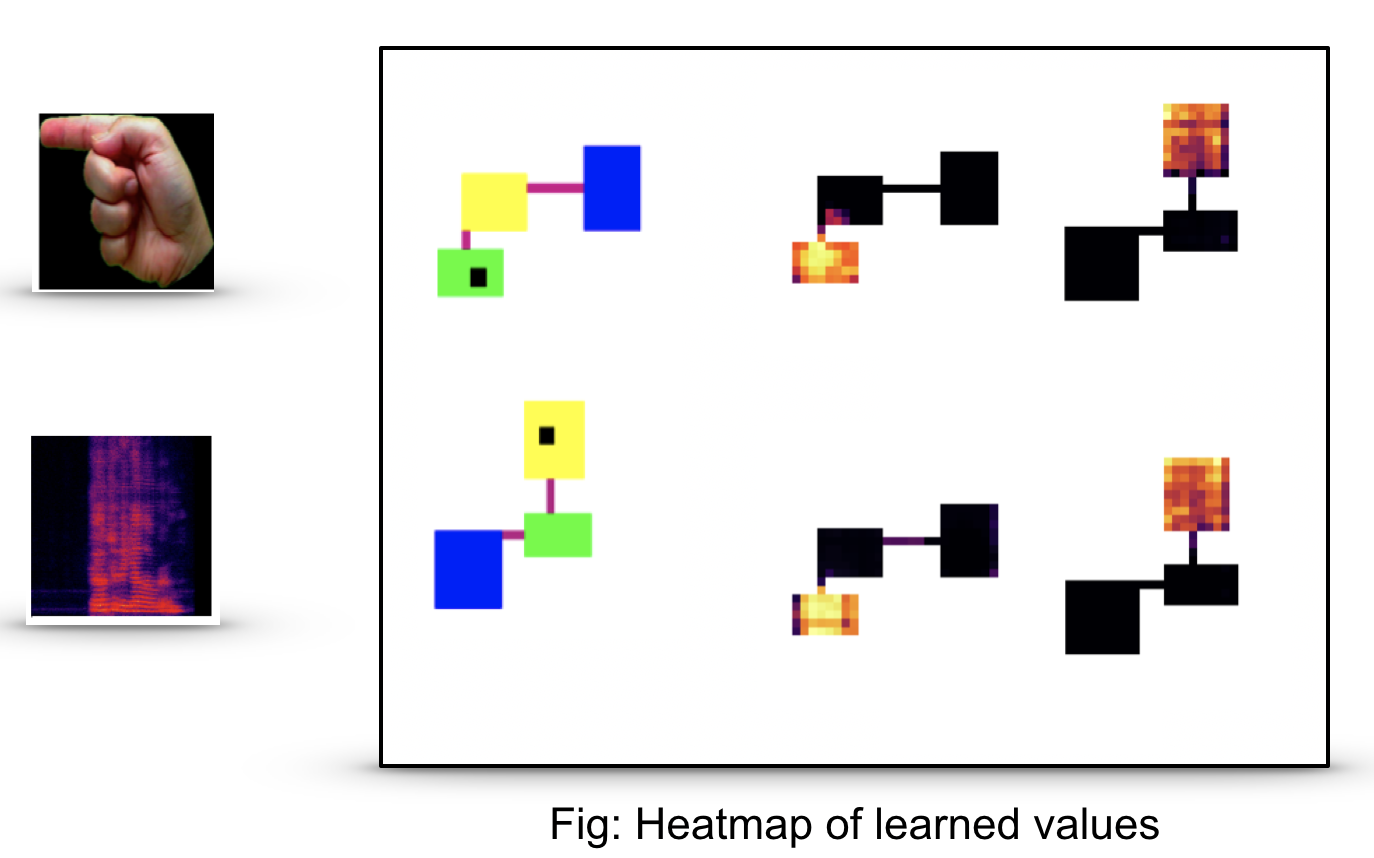
In reinforcement learning, we often define goals by specifying rewards within desirable states. One problem with this approach is that we typically need to redefine the rewards each time the goal changes, which often requires some understanding of the solution in the agents environment. When humans are learning to complete tasks, we regularly utilize alternative sources that guide our understanding of the problem. Such task representations allow one to specify goals on their own terms, thus providing specifications that can be appropriately interpreted across various environments. This motivates our own work, in which we represent goals in environments that are different from the agents. We introduce Cross-Domain Perceptual Reward (CDPR) functions, learned rewards that represent the visual similarity between an agents state and a cross-domain goal image. We report results for learning the CDPRs with a deep neural network and using them to solve two tasks with deep reinforcement learning.
This work was accepted into RLDM 2017.
Ashley D. Edwards, Charles L. Isbell, Atsuo Takanishi

Reinforcement learning problems are often described
through rewards that indicate if an agent
has completed some task. This specification can
yield desirable behavior, however many problems
are difficult to specify in this manner, as one often
needs to know the proper configuration for the
agent. When humans are learning to solve tasks,
we often learn from visual instructions composed
of images or videos. Such representations motivate
our development of Perceptual Reward Functions,
which provide a mechanism for creating visual task
descriptions. We show that this approach allows an
agent to learn from rewards that are based on raw
pixels rather than internal parameters.
This work was accepted into a 2016 IJCAI workshop, Deep Reinforcement Learning: Frontiers and Challenges.
Ashley D. Edwards, Michael L. Littman, Charles L. Isbell
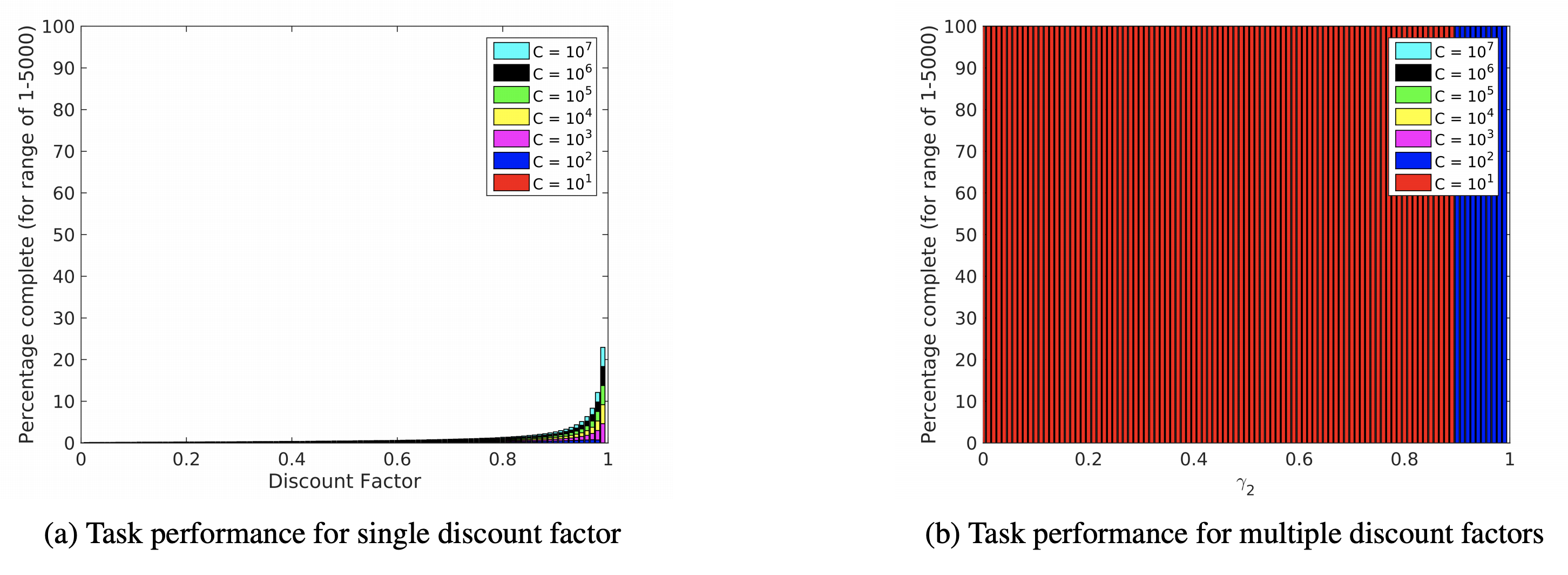
Reward engineering is the problem of expressing a target task for an agent in the form of rewards for a Markov decision process.
To be useful for learning, it is important that these encodings be robust to structural changes in the underlying domain; that is, the
specification remain unchanged for any domain in some target class. We identify problems that are difficult to express robustly via the
standard model of discounted rewards. In response, we examine the idea of decomposing a reward function into separate components,
each with its own discount factor. We describe a method for finding robust parameters through the concept of task engineering, which
additionally modifies the discount factors. We present a method for optimizing behavior in this setting and show that it could provide
a more robust language than standard approaches.
This work was accepted into RLDM 2015.
- Design: HTML5 UP